
Recently, 3D understanding has become popular to facilitate autonomous agents to perform further decisionmaking. However, existing 3D datasets and methods are often limited to specific tasks. On the other hand, recent progress in Large Language Models (LLMs) and Multimodal Language Models (MLMs) have demonstrated exceptional general language and imagery tasking performance. Therefore, it is interesting to unlock MLM’s potential to be 3D generalist for wider tasks. However, current MLMs’ research has been less focused on 3D tasks due to a lack of large-scale 3D instruction-following datasets. In this work, we introduce a comprehensive 3D instructionfollowing dataset called M3DBench, which possesses the following characteristics: 1) It supports general multimodal instructions interleaved with text, images, 3D objects, and other visual prompts. 2) It unifies diverse 3D tasks at both region and scene levels, covering a variety of fundamental abilities in real-world 3D environments. 3) It is a large-scale 3D instruction-following dataset with over 320k instruction-response pairs. Furthermore, we establish a new benchmark for assessing the performance of large models in understanding multi-modal 3D prompts. Extensive experiments demonstrate the effectiveness of our dataset and baseline, supporting general 3D-centric tasks, which can inspire future research.
Dataset Download: If you are interested in M3DBench dataset, you can download it here.
Comparison between M3DBench and other 3D VL datasets as well as 3D instruction datasets. M3DBench has the following characteristics: 1) A comprehensive instruction-following dataset tailored for 3D scenes. 2) Supporting multi-modal instructions that interleave text, coordinate, image, 3D object, and so on. 3) Encompassing diverse 3D visual-centric tasks that span a variety of fundamental abilities in real-world 3D environments, such as visual perception, scene understanding, spatial reasoning, navigation, and planning.

The statistics of the M3DBench. (a) The distribution of instructions based on the first word, where the inner circle of the graph represents the frequency of the first word’s occurrence, and the outer circle shows the frequency of verbs and nouns appearing in the instructions corresponding to that first word. (b) The word cloud of responses. (c) The distribution of instruction length. (d) The distribution of response length
We introduce a baseline model that connects scenes with interleaved multi-modal instructions and accomplishes diverse tasks using a unified decoder. Specifically, we utilize scene perceiver to extract scene tokens from 3D visual input. Multi-modal instructions are transformed into corresponding instruction tokens via their respective encoders. The scene tokens and multi-modal instruction tokens are then concatenated and fed into a frozen LLM, which generates the corresponding responses subsequently. During the training process, only the projectors are updated.
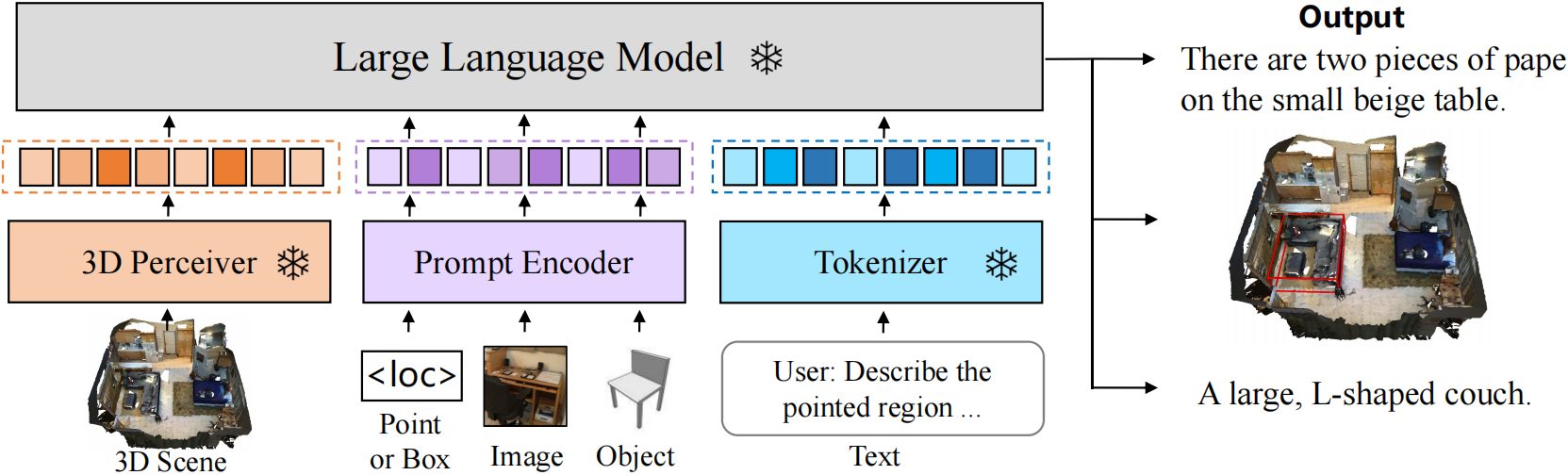
Utilizing the M3DBench benchmark, we aim to evaluate and report the capabilities of large models in real-world 3D environments. The benchmark comprises approximately 1,500 pairs of instruction-response pairs, encompassing both regional and scene-level tasks such as object localization, scene description, multi-round dialogue, planning, and more.
| Method | OL(ACC@0.25) | DC(C) | VQA(C) | EQA(C) | MR(C) | EP(C) | SD(GPT4) | MD(GPT4) |
|---|---|---|---|---|---|---|---|---|
| OPT-6.7B(PN++) | 3.09 | 17.01 | 336.96 | 212.12 | 363.87 | 133.94 | 9.87 | 40.97 |
| LLaMA-2-7B(PN++) | 1.60 | 22.05 | 379.05 | 194.09 | 378.17 | 253.09 | 27.89 | 44.74 |
| OPT-6.7B(TR) | 1.22 | 23.76 | 365.60 | 218.01 | 240.89 | 213.15 | 16.84 | 29.52 |
| LLaMA-2-7B(TR) | 3.57 | 20.72 | 356.42 | 179.33 | 351.96 | 114.91 | 27.37 | 38.61 |
*OL represents the model's ability for Object Localization, DC stands for Dense Caption, VQA for Visual Question Answering, EQA for Embodied Question Answering, MR for Multi-region Reasoning, EP for Planning. SD and MD denote Scene Description andMulti-round Dialogue, respectively. C is the abbreviation for CIDEr.
There are also outstanding concurrent works, such as: LAMM, 3D-LLM, Chat-3D, Point-Bind & Point-LLM, PointLLM, LEO, and LL3DA.
You might find many more by the time you are checking Awesome-LLM-3D and Awesome-Multimodal-Large-Language-Models.
@misc{li2023m3dbench,
title={M3DBench: Let's Instruct Large Models with Multi-modal 3D Prompts},
author={Mingsheng Li and Xin Chen and Chi Zhang and Sijin Chen and Hongyuan Zhu and Fukun Yin and Gang Yu and Tao Chen},
year={2023},
eprint={2312.10763},
archivePrefix={arXiv},
primaryClass={cs.CV}
}